Introduction to the Corroboration Index
 The corroboration index is a quantitative measure designed to assess the degree of agreement or consistency among a set of related articles. In the context of open-source intelligence (OSINT) where information reliability is paramount, the corroboration index provides a critical metric for determining how well different sources confirm or support each other’s content. This index is particularly valuable when analyzing news articles or reports that cover the same event or topic.
The corroboration index is a quantitative measure designed to assess the degree of agreement or consistency among a set of related articles. In the context of open-source intelligence (OSINT) where information reliability is paramount, the corroboration index provides a critical metric for determining how well different sources confirm or support each other’s content. This index is particularly valuable when analyzing news articles or reports that cover the same event or topic.
How the Corroboration Index is Calculated
The corroboration index is calculated through a multi-step process involving clustering and similarity analysis:
- Article Embedding: Each article snippet or summary is converted into a numerical vector representation using a sentence embedding model. This allows the textual content to be quantitatively compared.
- Clustering: Articles are grouped into clusters based on their content similarity. The clustering algorithm, such as DBSCAN, identifies groups of articles that describe similar events or topics.
- Similarity Matrix: Within each cluster, a similarity matrix is generated, capturing the pairwise similarities between the articles. The similarity scores typically range from 0 to 1, with 1 indicating perfect similarity.
- Corroboration Index Calculation: For each cluster, the corroboration index is computed as the product of the average similarity score within the cluster and the number of articles in that cluster. This index provides a combined measure of how many articles are in agreement and how strong that agreement is. The formula is:
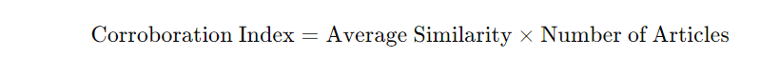
Interpretation of the Corroboration Index
The corroboration index offers a way to gauge the reliability of information by assessing how well it is corroborated across multiple sources:
- High Corroboration Index: A high index indicates that the articles in the cluster are not only numerous but also highly similar in content. This suggests strong corroboration, meaning the reported information is likely reliable as it is consistently supported across multiple sources. For example, in the case of a listeriosis outbreak, a high corroboration index among articles might indicate widespread reporting on the same outbreak, reinforcing the credibility of the information.
- Low Corroboration Index: A low index may occur if the cluster contains few articles or if the articles within the cluster are not very similar. This suggests weaker corroboration, implying that the information may not be as reliable or is less consistently reported. Such a scenario might arise in cases where the event is less well-covered or when the sources offer differing perspectives.
Application in Biosurveillance
In biosurveillance, where timely and accurate information is critical, the corroboration index helps analysts prioritize which pieces of information to act upon. For instance, in monitoring disease outbreaks, clusters of news articles with high corroboration indices can be flagged for further investigation or immediate action, while those with lower indices might be deprioritized or flagged for further verification. The corroboration index serves as a powerful tool for assessing the reliability of information in contexts where multiple sources report on the same event or topic. By combining both the number of corroborating articles and the degree of their agreement, the corroboration index provides a clear, interpretable metric that can guide decision-making in environments where data accuracy and consistency are critical, such as in OSINT and biosurveillance.
Weighting:
- Weighting Factors: When weighting factors are applied, a weighting factors dictionary assigns different weights to different types of data sources. These weights reflect the relative importance or reliability of each source.
- Apply Weighting: A weighting function multiplies the embeddings of each article by its corresponding weight based on its data type.
- Weighted Similarity Matrix: The weighted embeddings are then used to compute the similarity matrix, which reflects not only the content similarity but also the reliability or importance of the data sources.
- Weighted Corroboration Index: The corroboration index is calculated using the weighted similarity matrix. The result is a weighted corroboration index that gives more importance to certain types of data.
Weighting Interpretation:
- Higher Weighted Corroboration Index: If an article cluster includes data types with higher weights (e.g., sensor data), the corroboration index will be higher, indicating stronger and more reliable corroboration.
- Flexibility: This approach allows you to tailor the corroboration index to the specific context of your analysis, ensuring that more reliable data sources have a greater influence on the overall assessment of information consistency.
Incorporating a weighting factor into the corroboration index allows the corroboration algorithm to account for the varying reliability and importance of different data sources. This makes the corroboration index more reflective of the true confidence level in the information being analyzed, particularly in contexts where some data types are inherently more trustworthy than others.
Incorporating Temporal Dynamics
- Time Decay Factor: The corroboration index includes a variable time decay factor that reduces the influence of older articles on the corroboration index. This ensures that more recent information, which may be more relevant and accurate, has a greater impact on the index.
- Event Timeline Alignment: The algorithm also attempts to align articles based on the timing of events they describe (if a publication date is available). Articles that are published closer together in time might be considered more corroborative of each other than those published far apart.
Use of Advanced Similarity Measures
- Contextual Similarity: The similarity indexing function can be configured to use either the default cosine similarity or BERT-based similarity for more advanced similarity measurements that consider context. This can better capture nuanced agreements between articles but requires a trade-off in computational performance and speed.
- Thematic Consistency: A topic modeling flag (e.g., BERTopic) can be set to ensure that articles within a cluster not only have similar wording but also cover the same themes or topics. This option incorporates thematic consistency into the corroboration index.
Incorporating Confidence Scores
- Source Reliability: Confidence scores are assigned to different sources based on their historical reliability. For instance, a reputable news outlet might have a higher confidence score than a lesser-known blog.
- Confidence-Weighted Index: Confidence scores are integrated into the corroboration index calculation. Articles from more reliable sources contribute more heavily to the index.
Accounting for Contradictory Information
- Contradiction Detection: The corroboration index implements a mechanism to detect and penalize contradictory information within a cluster. Articles that directly contradict each other lower the corroboration index, as this suggests a lack of consensus.
- Sentiment Analysis: The corroboration index uses sentiment analysis to detect inconsistencies in the sentiment or stance of articles. If some articles in a cluster are positive and others are negative about the same event, this might indicate a weaker corroboration.
Normalizing the Corroboration Index
- Relative Normalization: The corroboration index normalizes each topic to allow for easier comparison across different contexts. For example, the algorithm scales the index from 0 to 1 within each cluster.
Multi-Layered Corroboration
- Layered Corroboration: The corroboration index output is broken down into multiple layers: content similarity, source reliability, and temporal proximity. Each layer contributes to the overall index, providing a more nuanced assessment.
- Hierarchical Corroboration: The corroboration index implements a hierarchical approach where corroboration is first assessed within smaller, more specific clusters (e.g., by region or subtopic) and then aggregated to provide an overall corroboration index.
Conclusion and Key Takeaways
The Opensource Intelligence Corroboration Index is a powerful tool designed to enhance the reliability and consistency of data sourced from diverse open-source intelligence (OSINT) platforms. By employing advanced NLP techniques and machine learning algorithms, the index provides a quantitative measure of agreement among related articles, offering a critical metric for assessing the credibility of information.
Key Takeaways:
- Enhanced Information Reliability: The corroboration index offers a robust method to evaluate the consistency of information across multiple sources. High indices indicate strong corroboration, enhancing the trustworthiness of the data, while lower indices suggest the need for further verification.
- Multi-Step Calculation Process: The index is derived through a comprehensive process involving article embedding, clustering, and similarity analysis, culminating in a metric that reflects both the number of corroborating articles and the strength of their agreement.
- Applications in Critical Domains: Whether in healthcare, finance, politics, or biosurveillance, the corroboration index helps prioritize reliable information, aiding timely and informed decision-making.
- Incorporation of Weighting Factors: By integrating weighting factors, the index can be tailored to emphasize more reliable data sources, thus providing a context-sensitive assessment of information consistency.
- Temporal Dynamics and Advanced Similarity Measures: The inclusion of time decay factors and advanced similarity measures ensures that the most recent and contextually similar information has a greater influence on the index, enhancing its accuracy and relevance.
- Handling Contradictory Information: The index accounts for contradictory information within clusters, penalizing inconsistencies to present a more nuanced and reliable measure of corroboration.
- Normalization and Multi-Layered Corroboration: Normalizing the index for easier comparison and implementing a hierarchical approach provides a detailed and scalable assessment of information reliability.
In summary, the Opensource Intelligence Corroboration Index represents a significant advancement in the field of OSINT, offering a sophisticated, multi-faceted approach to assessing the reliability of information used in decision support systems. By combining various layers of analysis and incorporating weighting, temporal dynamics, and advanced similarity measures, the index provides a comprehensive tool for enhancing confidence in open-source data.


